Que caches-tu sous les transistors ?

Début juin, lors du Computex, AMD présentait ses nouvelles gammes de processeurs exploitant sa nouvelle architecture Zen 5 : les Ryzen 9000 pour les ordinateurs de bureau et les Ryzen AI 300 pour les portables Copilot+.
Nous n’avions toutefois que peu d’informations sur l’architecture elle-même, si ce n’est une augmentation de l’IPC (instructions par cycle d’horloge) de 16 % sur Zen 5 par rapport à Zen 4 et 50 TOPS sur XDNA 2 (16 TOPS sur la génération précédente).
Les améliorations d’AMD sur son architecture Zen 5
Pour rappel, les grandes lignes du fonctionnement des processeurs Ryzen reste un peu le même au fil des générations. Le travail commence par la Branch Prediction où les instructions arrivent. Elles sont ensuite traitées dans un pipeline, via trois étapes : Fetch, Decode et Exec. Cela correspond respectivement à la récupération des informations, à leur décodage (c’est-à-dire la transformation des instructions en micro-opérations) et enfin à leur exécution.
Dans de nouveaux documents, AMD annonce la présence d’un dual pipeline fetch (lors de la récupération/chargement des instructions) sur Zen 5, contre un seul sur Zen 4. Même chose pour le décodage qui passe à 2x 4-wide, contre un seul auparavant. Enfin, pour la fonction qui dispatche les instructions pour ensuite les exécuter dans le pipeline, on passe de 6 à 8-wide.
AMD annonce une prédiction de branche améliorée dans son ensemble, en comparaison bien évidemment à la génération précédente. Résultat des courses, une latence en baisse et une bande passante en hausse. Les images ci-dessous résument les changements :
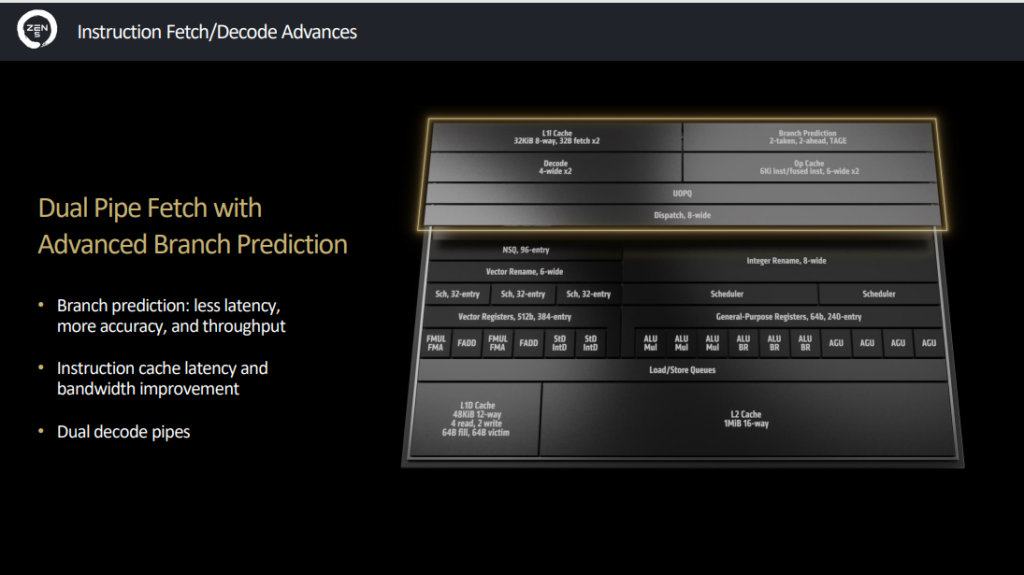
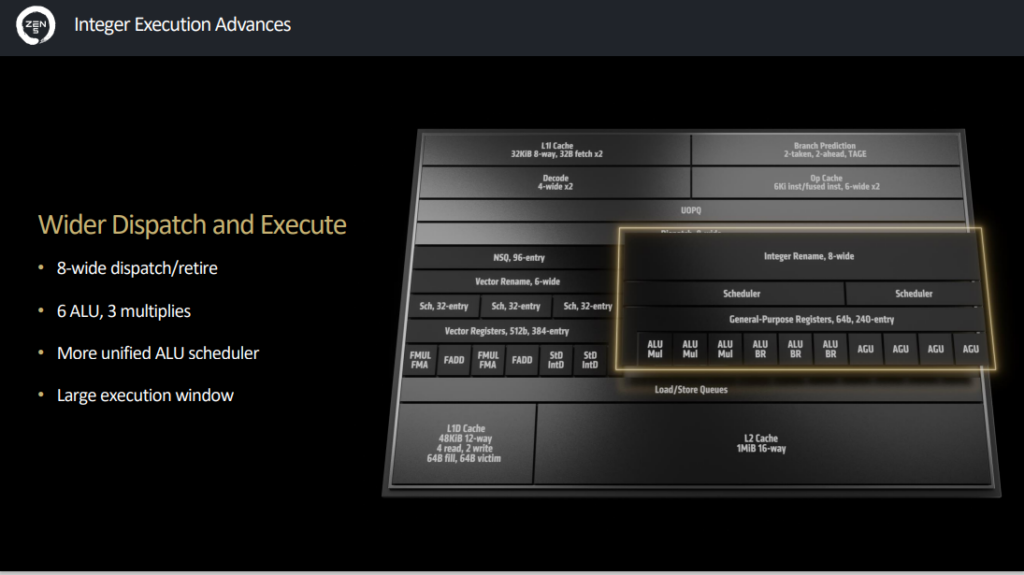

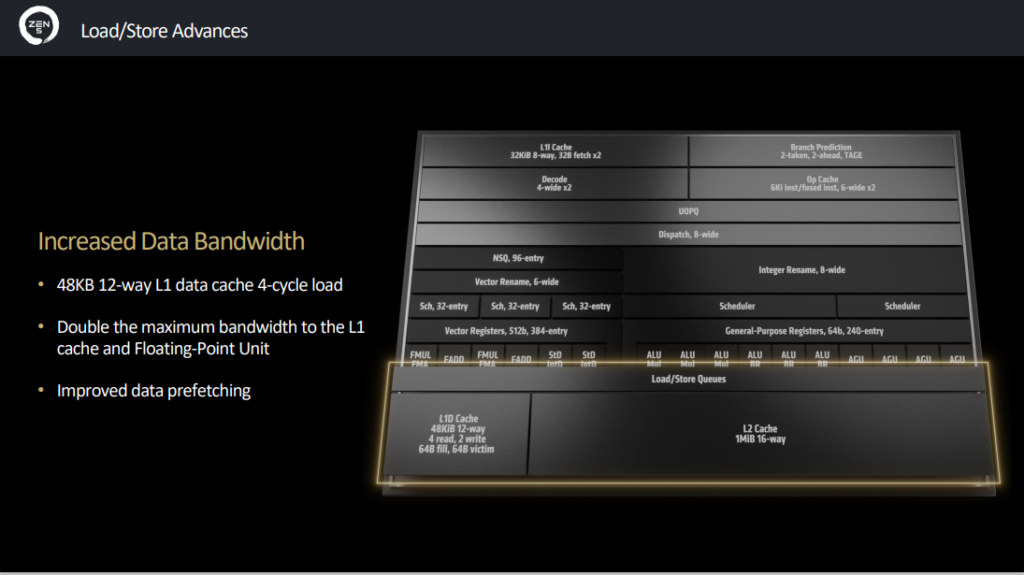
Six ALU, quatre AGU, bus de 512 bits en FP
Toujours sous le capot, Zen 5 a d’autres améliorations à mettre en avant : six ALU (Arithmetic Logic Unit) là où Zen 4 n’en avait que quatre, une hausse également des AGU (Address Generation Unit) de trois à quatre.
Sur la partie floating point (FP ou nombre à virgule flottante, la zone de gauche au milieu dans les graphiques du dessus), Zen 5 propose désormais un bus complet de 512 bits au lieu de 2x 256 bits auparavant. Cela permet ainsi d’améliorer les performances sur le jeu d’instructions AVX-512.
Enfin, le cache L1 pour les données (L1D, à ne pas confondre avec L1I avec un I pour instructions) passe de 32 Ko (8-way) à 48 Ko (12-way). AMD affirme avoir également doublé la bande passante maximale du cache L1 et du FPU (Floating Point Unit).
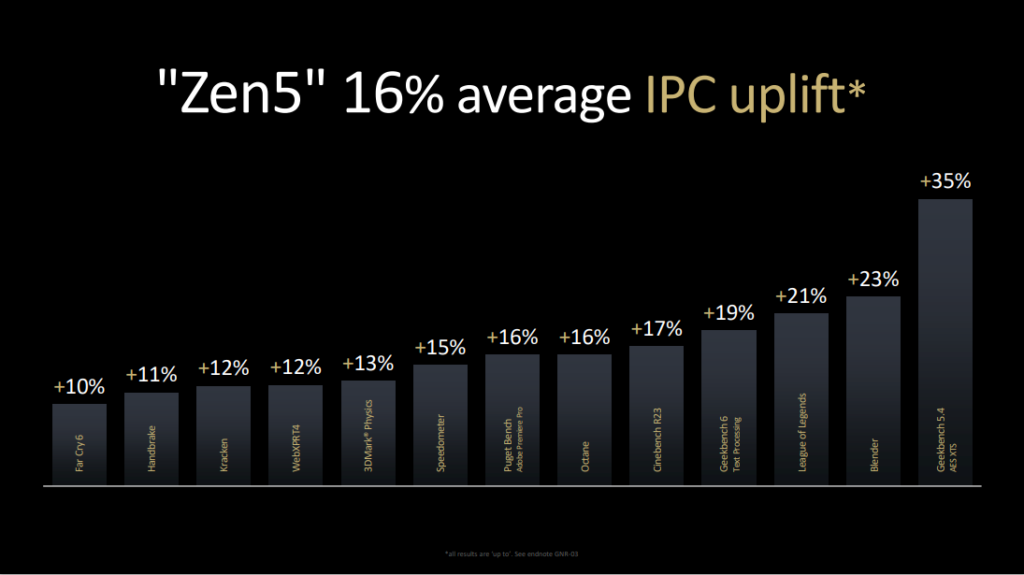
Des gains variables, avec 16 % en moyenne sur l’IPC
Tout cela donne donc une hausse, toujours selon les chiffres d’AMD, de 16 % sur l’IPC. Bien évidemment, les gains sont variables selon les cas : jusqu’à 10 % sur FarCry 6, 11 % sur Handbrake, 13 % sur 3DMark Physics, 17 % sur Cinebench R23, 23 % sur Blender et jusqu’à 35 % sur Geekbench 5.4.
Attention, il ne s’agit ici que de l’architecture Zen 5, pas de la version allégée des cœurs Zen 5c. Ces derniers seront par exemple présents dans les Ryzen AI 9 HX 370 et AI 9 365. Le premier dispose de 12 cœurs avec 4x Zen 5 et 8x Zen 5c, contre 10 cœurs pour le second avec 4x Zen 5 et 6x Zen 5c.

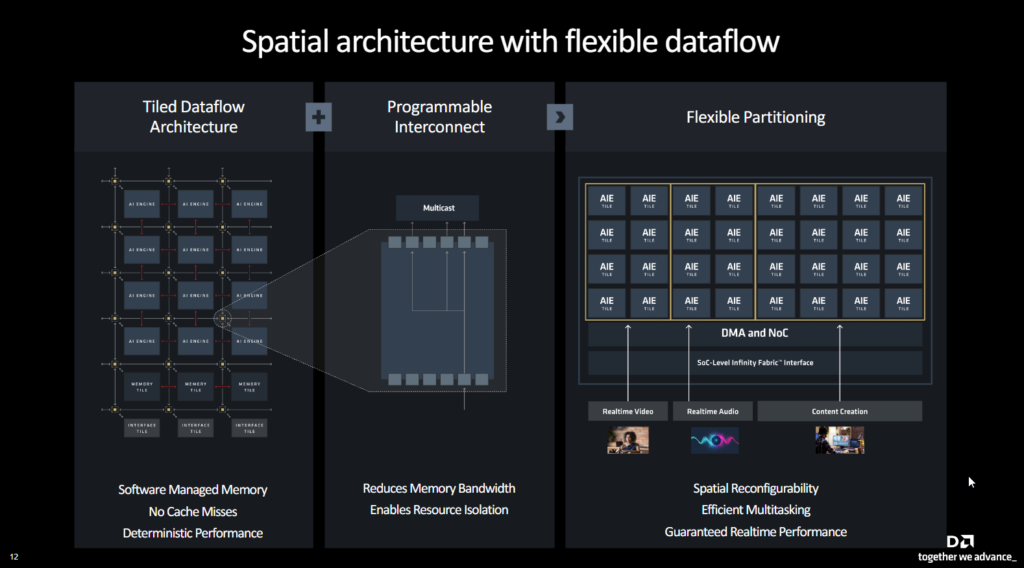
XDNA 2 : plus de tuiles AI pour l’IA
AMD propose aussi de nouveaux détails sur son architecture XDNA 2, utilisée par son NPU de nouvelle génération à 50 TOPS. XDNA utilise pour rappel un « réseau en mosaïque de processeurs AI Engine. Chaque “tuile” AI Engine inclut un processeur vectoriel, un processeur scalaire, ainsi que des mémoires de programme et données locales ». De 20 tuiles sur XDNA, AMD passe à 32 tuiles sur XDNA 2, avec 1,6x plus de mémoire par NPU (pour passer de 20 à 32 tuiles, on multiplie aussi par 1,6).
« Contrairement aux architectures traditionnelles qui nécessitent une récupération répétée des données issues des caches (une opération qui consomme de l’énergie), AI Engine utilise des mémoires sur puce et un flux de données personnalisé pour permettre un calcul efficace et à faible consommation pour l’IA et le traitement du signal », explique AMD.


Block FP16 : vitesse du 8 bits avec précision du 16 bits ?
AMD explique aussi que son NPU prend en charge les Block FP16, avec une caractéristique très intéressante sur le papier : les performances du 8 bits, mais avec la précision du 16 bits.
Ce tour de « magie » est en fait un tour de « passe-passe » : l’exposant (sur 8 bits) est le même pour toutes les données, les calculs ne se font donc plus que sur la mantisse (sur 8 bits), pas sur la totalité du nombre. Nous avons pour rappel consacré un dossier aux nombres en informatique, avec le fonctionnement des exposants et des mantisses (ou significande).

Dans l’exemple ci-dessous, on passe d’un total de 128 bits pour 8 éléments (sur 16 bits, soit 16 x 8 = 128) à 72 bits. On a 8 bits pour chaque élément (soit 64 bits) et une seule fois 8 bits supplémentaires pour l’exposant partagé entre toutes les données, soit 72 bits au total.
Comme un air de Microsoft Floating Point
Si AMD est le premier à intégrer cette fonctionnalité dans ses processeurs, ce n’est pas une exclusivité de la marque. Intel pourrait faire de même avec sa prochaine gamme Lunar Lake. De plus, Microsoft en parlait déjà en 2020 avec son Microsoft Floating Point (MSFP) qui consistait à mettre en commun l’exposant.


Avec XDNA 2 sur les Ryzen AI 300, AMD annonce des performances multipliés par cinq par rapport aux Ryzen 7040, avec une consommation doublée seulement. Le NPU des Ryzen 7040 est en effet donné pour 10 TOPS, contre 16 TOPS pour les Ryzen 8040 et 50 TOPS pour les Ryzen AI 300.
En 2026, la société annoncera XDNA3 avec un ratio performances/watt encore amélioré, mais sans plus de détails.
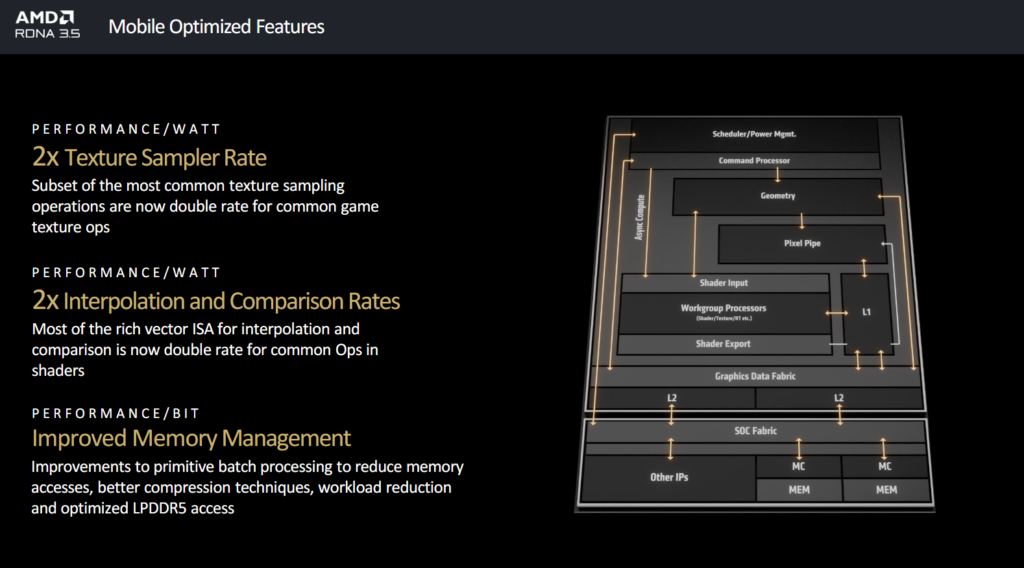
RDNA 3.5 ; jusqu’à 32 % de performances par watt en plus
Enfin, AMD parle rapidement de son architecture GPU intégrée dans ses processeurs mobiles Ryzen AI 300 : RDNA 3.5. L’accent est mis sur les performances par watt pour limiter la consommation et augmenter la durée de vie de la batterie. Mais les détails techniques manquent à l’appel.
À consommation égale (15 watts), RDNA 3.5 aurait des performances par watt jusqu’à 32 % supérieures à celle de RDNA 3 dans 3DMark Timespy. On descend à 19 % dans Night Raid, toujours sur 3D Mark.

Nous reviendrons dans une prochaine actualité sur les processeurs AMD Ryzen 9000, dont la sortie est prévue pour le 31 juillet.